
Ollama on Cloud Run with GPU in less than 20 seconds! 🤯 🚀
Want to deploy powerful open-source language models quickly and efficiently? This guide shows you how to run Ollama with the new Gemma 3…


Want to deploy powerful open-source language models quickly and efficiently? This guide shows you how to run Ollama with the new Gemma 3 models on Google Cloud Run, leveraging GPU acceleration for blazing-fast inference. We’ll achieve deployment in under 20 seconds, explore the costs involved, and benchmark the performance of Gemma 3. This is a practical guide focusing on speed and ease of use.
· Why Cloud Run? Speed, Simplicity, and Scalability
· Deploying Ollama on Cloud Run with GPU
∘ Important Considerations: GCSFuse and Memory Limits
· Cloud Run GPU Pricing
· Gemma 3 Performance on Cloud Run GPU 🚀
∘ Update: Gemma 3 27B Performance with Ollama 0.6.1 (March 17, 2025)
· Other Cloud Run goodies
· In Conclusion
Gemma 3 is Google’s exciting family of open-weight generative AI models, offering impressive capabilities for text and multimodal applications. Key features include:
Multimodal Input: Process both images and text.
Large Context Window: Supports 128K tokens for richer, more context-aware responses.
Language Support: Over 140 languages supported.
Varied Sizes: Available in 1B, 4B, 12B, and 27B parameter sizes to fit different resource constraints.
Open Weights & Commercial Use: Freely available with permissions for responsible commercial applications.
Gemma 3 model overview | Google AI for Developers
Gemma is a family of generative artificial intelligence (AI) models and you can use them in a wide variety of…ai.google.dev
Why Cloud Run? Speed, Simplicity, and Scalability
Cloud Run is a fully managed serverless platform that allows you to run stateless containers on Google Cloud. It’s an ideal choice for deploying Ollama for the following reasons:
Rapid Deployment: Get your model up and running in seconds.
Automatic Scaling: Handles traffic spikes effortlessly.
Pay-per-second.
GPU Support: Accelerate inference with powerful GPUs.
Deploying Ollama on Cloud Run with GPU
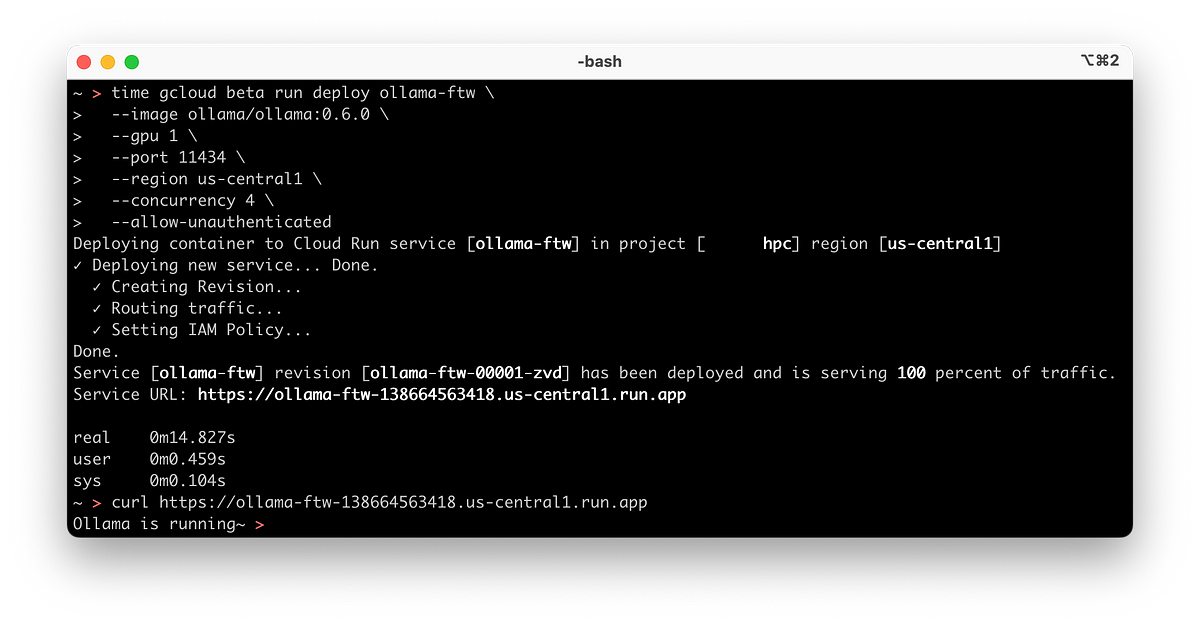
The screenshot featured at the beginning of this work shows Ollama running in less than twenty seconds but the Cloud Run command there is a bit limited. For a more robust deployment we’re gonna do what follows:
gcloud beta run deploy ollama-ftw \
--image ollama/ollama:0.6.1 \
--gpu 1 \
--gpu-type nvidia-l4 \
--set-env-vars OLLAMA_KEEP_ALIVE=-1 \
--cpu 4 \
--memory 16Gi \
--concurrency 4 \
--max-instances 2 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--port 8080 \
--allow-unauthenticated \
--set-env-vars OLLAMA_HOST=0.0.0.0:8080 \
--add-volume name=models,type=cloud-storage,bucket=<MODEL BUCKET NAME> \
--add-volume-mount volume=models,mount-path=/root/.ollama \
--set-env-vars OLLAMA_MODELS=/root/.ollama/models \
--timeout 3600 \
--region us-central1Note the following important flags in this command:
--image ollama/ollama:0.6.1the container image used by Cloud Run.--gpu 1 --gpu-type nvidia-l4the quantity and type of GPU exposed to the Cloud Run service.--set-env-vars OLLAMA_KEEP_ALIVE=-1keeps a model indefinitely loaded in vRAM. This allows for quicker response times if you’re making numerous requests to the LLM.--cpu 4 --memory 16Githe CPU and Memory resources of the Cloud Run service, which is also the minimum when using a GPU (be aware that respectively 8 and 32Gi are the recommended values and required to run Gemma 3 27B) — Update (March 19, 2025) Ollama version 0.6.2 resolves an issue where Gemma 3 models previously consumed excessive system memory. With this update, 16 GiB of system RAM is now enough, even for the Gemma 3 27B model.--concurrency 4 --set-env-vars OLLAMA_NUM_PARALLEL=4defines the maximum concurrent requests per instance. The Cloud Run service and Ollama config need to match here.--max-instances 2is the maximum number of instances when scaling out.--port 8080 set-env-vars --OLLAMA_HOST=0.0.0.0:8080defines which port the Ollama container is binding to.--allow-unauthenticatedwhile not recommended, this it’s an easy way to get your inference engine exposed over the Internet in a few seconds.--add-volume name=models,type=cloud-storage,bucket=<MODEL BUCKET NAME> --add-volume-mount volume=models,mount-path=/root/.ollama set-env-vars OLLAMA_MODELS=/root/.ollama/modelsoptions to use the GCS Fuse integration in Cloud Run and persistently store the models. Make sure of using a bucket available in the same region as the Cloud Run service.--timeout 3600ensures that long responses (and model loading time) won’t be an issue, extended from the default 300 seconds.--region us-central1the region where we want to run our Cloud Run service with GPUs, specifically at the time of writing, only four regions are available: us-central1 (Iowa), asia-southeast1 (Singapore), europe-west1 (Belgium), and europe-west4 (Netherlands).
Google has also published an official paper about deployig serverless AI with Gemma 3 on Cloud Run.
Run LLM inference on Cloud Run GPUs with Ollama | Cloud Run Documentation | Google Cloud
To configure the Google Cloud CLI for your Cloud Run service: Set your default project: Click the icon to replace the…cloud.google.com
Important Considerations: GCSFuse and Memory Limits
While the above setup is fast, there’s a potential issue with using GCSFuse for large models. GCSFuse uses an in-memory cache before writing the entire file to Cloud Storage. This can lead to no space left on device errors when pulling large models like Gemma 3 27B, which is actually an out-of-memory error.
{"error":"open /root/.ollama/blobs/sha256-123-partial-6: no space left on device"}Cloud Run Job GCSFuse Out of Memory
We're experiencing out of memory errors when running a cloud run job that only writes files to a mounted bucket. The…stackoverflow.com
For larger models (rule of thumb: anything larger than 50% of the total memory available in the container) consider using Filestore, coupled with Direct VPC egress, for improved network performance.
Compare Direct VPC egress and VPC connectors | Cloud Run Documentation | Google Cloud
This page is for networking specialists who want to compare the following methods for sending egress (outbound) traffic…cloud.google.com
--add-volume=name=models,type=nfs,location=<Filestore-IP>:/models \
--add-volume-mount volume=models,mount-path=/root/.ollama \
--subnet us-central1 \
--vpc-egress=allConfigure NFS volume mounts for services | Cloud Run Documentation | Google Cloud
This page shows how to mount an NFS file share as a volume in Cloud Run. You can use any NFS server, including your own…cloud.google.com
Cloud Run GPU Pricing
Let’s talk money. A Cloud Run service in us-central1 with an NVIDIA L4 GPU, 8vCPU, and 32GB of memory costs approximately:
Per-second: $0.000395
Per-minute: $0.023682
Per-hour: $1.420920
Per-month (730 hours): $1,037.27
Pricing | Cloud Run | Google Cloud
Review pricing for Cloud Runcloud.google.com
Gemma 3 Performance on Cloud Run GPU 🚀

Due to memory constraints, running the full Gemma 3 27B model was not feasible. At 4-bit quantization we still need about 21GB of memory.
time=2025-03-12T23:38:09.586Z level=INFO source=types.go:130 msg="inference compute" id=GPU-a7d5c53f-acd7-98c4-f088-29799fb0748d library=cuda variant=v12 compute=8.9 driver=12.2 name="NVIDIA L4" total="22.2 GiB" available="22.0 GiB"With the 12B parameters model, Q4_K_M quantization (a technique that compresses the model weights to 4 bits per parameter to reduce memory usage and improve speed), the configuration above using Ollama 0.6.0, we achieved an average of 25.23 tokens/second when answering the academical question “Why is the sky blue?”. This translates to an estimated cost of $0.0000115 per token. Honestly, not bad. I plan to explore vLLM to see if we can further improve inference speed and reduce costs.
Update: Gemma 3 27B Performance with Ollama 0.6.1 (March 17, 2025)
This update details performance testing of the Gemma 3 27B model, leveraging the recently released Ollama 0.6.1. This version of Ollama incorporates improved memory estimation, enabling successful execution of the full 27 billion parameter model.
The chart below provides a comprehensive performance overview for all Gemma 3 models (1B, 4B, 12B, and 27B), illustrating the total processing duration (in seconds), the response token generation rate (tokens per second), and the cost per token. These tests utilized Ollama’s default Q4_K_M quantization and were conducted on a Cloud Run Service configured with 8 vCPUs, 32GB of RAM, and an NVIDIA L4 GPU.
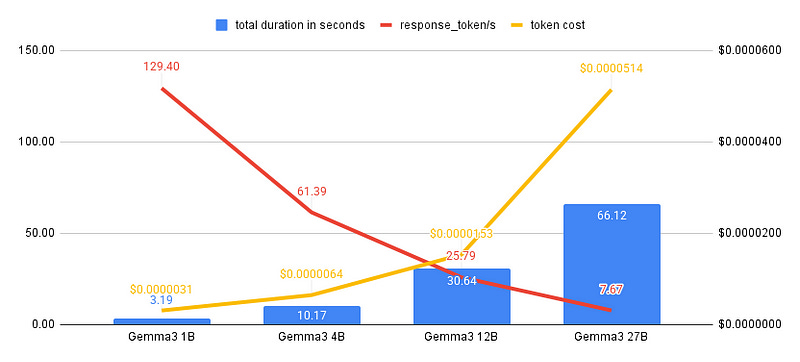
While the Gemma 3 27B model was successfully deployed and functional, its performance on the L4 GPU with 24GB of GDDR6 memory resulted in a token generation rate of 7.67 tokens per second. This indicates that the 27B model operates at the slower end of the performance spectrum on this hardware, likely due to memory bandwidth limitations. There were no major changes observed in the 12B model’s performance; as expected, models with fewer parameters exhibited faster response times and lower cost per token.
Update (March 19, 2025) Ollama version 0.6.2 resolves an issue where Gemma 3 models previously consumed excessive system memory. With this update, 16 GiB of system RAM is now enough, even for the Gemma 3 27B model.
Other Cloud Run goodies
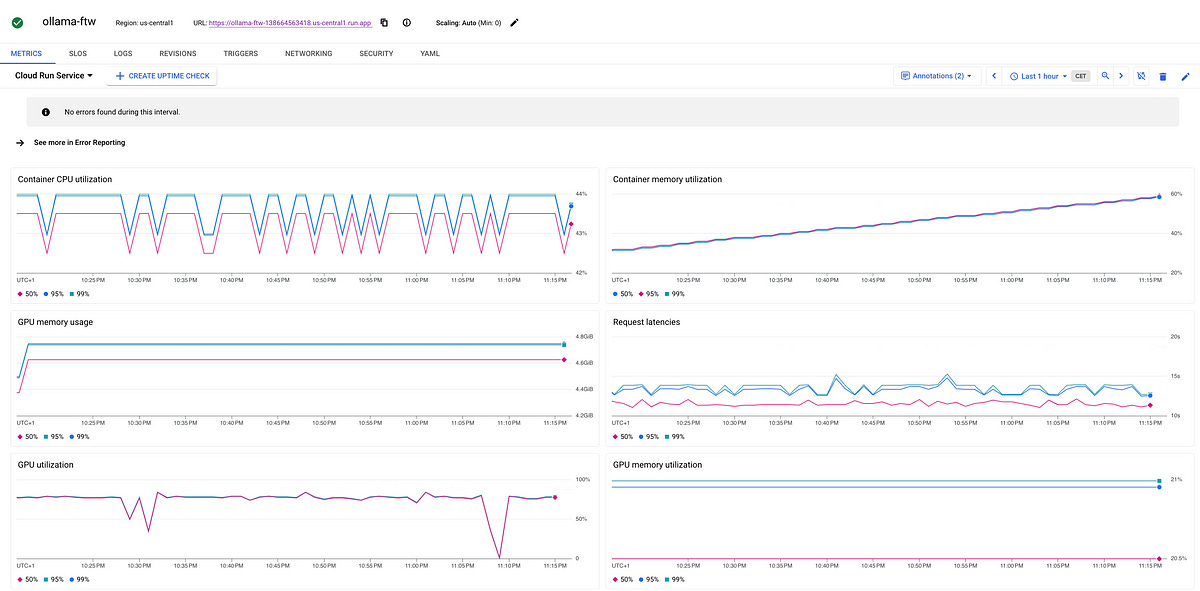
Beyond speed, Cloud Run provides built-in metrics and logging for easy monitoring and debugging. You can track CPU utilization, memory usage, request latency, and error rates directly from the Cloud Console.
In Conclusion
In conclusion, this work underscores Cloud Run’s transformative potential as more than just a deployment platform; it’s an accelerator for democratizing access to cutting-edge, open-source AI. The ability to launch Ollama with GPU acceleration in under 20 seconds isn’t merely a speed benchmark; it’s a paradigm shift for AI development. Imagine the possibilities: instantly deployable Gemma 3-powered chatbots with nuanced multilingual understanding, rapidly prototyped multimodal applications analyzing images and text in real-time, or scalable AI-driven services that adapt to demand with serverless efficiency.
The open-weight nature of Gemma 3, coupled with Cloud Run’s accessibility, empowers developers to build innovative and responsible AI solutions, free from the constraints of proprietary ecosystems. This combination unlocks a future where sophisticated AI is not just the domain of large corporations, but readily accessible to startups, researchers, and individual developers alike.
While considerations around memory management, especially for the largest Gemma 3 models, remain important, they also drive innovation in optimization techniques and model selection. This is not a roadblock, but an invitation to explore efficient quantization, model distillation, and the strategic use of Gemma 3’s varied sizes to match specific application needs.
Ultimately, the speed and simplicity we’ve demonstrated are not just technical advantages; they are catalysts for innovation, inviting you to explore the vast and exciting potential that awaits at the intersection of serverless cloud and open-source AI models like Gemma 3.